Multiple regression
Gabriel Singer
21.01.2025
Multiple linear regression model
Multiple metric continuous independent predictors are used to predict
one metric response variable.
Model formulation: linear combination of k predictors: \[
\mathbb{E}(y) =\beta_0+\beta_1X_1+\beta_2X_2+...+\beta_pX_p
\]
- \(\beta_0\) is the intercept
- \(\beta_1...\beta_p\) are
partial regression coefficients for \(X_1...X_p\)
- The change in \(\mathbb{E}(y)\) per
unit change in an \(X_j\) holding all
other \(X\)-variables constant
- \(\beta_0...\beta_p\) are estimated
by \(b_0...b_p\) from the sample.
Why
doing a MLR? Two fundamentally different motivations:
- Hypothesis testing: I have clear hypotheses about every individual
variable \(X_i\), potentially even
including interactions.
- Predictive model building: I have little idea about relationships of
relationships but seek a “good” model. This includes explorative
approaches where “potential” predictors are identified.
Multiple linear regression model
Using matrix notation:
\[
\hat{y} = \mathbf{X}\mathbf{B}
\]
\(\mathbf{B}\) is the
parameter vector
\(\mathbf{X}\) is the design
matrix
\[
\mathbf{X} = \begin{bmatrix}
1 & x_{1,1} & x_{1,2} & \dots & x_{1,p} \\
1 & x_{2,1} & x_{2,2} & \dots & x_{2,p} \\
\vdots & \vdots & \vdots & \dots & \vdots \\
1 & x_{n,1} & x_{n,2} & \dots & x_{n,p} \\
\end{bmatrix}
\]
\[
\begin{aligned}
\mathbb{E}(y) = \hat{y} & = \mathbf{X}\mathbf{B} \\
y &= \mathbf{X}\mathbf{B} + \epsilon \\
\epsilon & \sim \mathcal{N}(0, s_\epsilon)
\end{aligned}
\]
The equation is a linear system and can be solved
with linear algebra by OLS, minimizing the sum of squared residuals:
\[
\mathrm{min}: \sum \epsilon^2 = \sum \left (\mathbf{X}\mathbf{B} - y
\right)^2
\]
Multiple linear regression: Hypotheses
- \(\mathbf{H_{0,regression}}\):
All partial regression coefficients are zero.
- The model (i.e., the linear system \(\mathbf{XB}\)) does not explain any of the
variation in \(y\).
- Test with ANOVA as with linear regression against a null model (with
no predictors).
- \(\mathbf{H_{0,coef_j}}\):
An individual partial regression coefficient, the slope of the
relationship between \(y\) and \(x_j\), is zero.
- with \(p\) predictors, there are
\(p\) such hypotheses.
- test with a \(t\)-statistic
- build a confidence limit for the slope of \(x_j\)
Multiple linear regression: Hypotheses
- \(\mathbf{H_{0,regression}}\):
All partial regression coefficients are zero.
- The model (i.e., the linear system \(\mathbf{XB}\)) does not explain any of the
variation in \(y\).
- Test with ANOVA as with linear regression against a null model (with
no predictors).
- \(\mathbf{H_{0,coef_j}}\):
An individual partial regression coefficient, the slope of the
relationship between \(y\) and \(x_j\), is zero.
- with \(p\) predictors, there are
\(p\) such hypotheses.
- test with a \(t\)-statistic
- build a confidence limit for the slope of \(x_j\)
Comparing effects using
slopes
Do not compare p-values to determine which predictor
is “better”
Rather, compare standardized effects
Either standardize all predictors (especially if \(s_{x_1} >> s_{x_2}\)) or standardize
the coefficients.
\[
{b_j}^*=b_j\frac{s_{X_j}}{s_Y}
\]
Higher \({b_j}^*\) means stronger
influence of \(x_j\). Note that in
software output \({b_j}^*\) is often
referred to as \(\beta_j\).
To express uncertainty for a regression slope, use confidence
intervals. For the t-statistic use \(d.f.=n-(p+1)\) where \(n\) is sample size and \(p\) is the number of involved predictors in
the model.
Multiple linear regression: Goodness of fit
- Explained variance: multiple \(R^2\)
- Similar interpretation as with simple LR: the percentage of
variation of Y explained by all X variables.
BUT: adding predictors (even random numbers) will always increase
\(R^2\) (by making the model more
flexible)
One solution is Adjusted \(R^2\): penalises \(R^2\) for additional model complexity.
\[
{R^2}_{adj}=1-\frac{SS_{res}}{SS_{tot}}\times\frac{n-1}{n-p}
\]
Comparing effects using
\(R^2\) partitioning
May be useful in particular cases, examples: \[
Flux=k \cdot \Delta C
\] \[
\log Flux=\log k + \log \Delta C
\] Fitting a model to a dataset here gives \(R^2=1\) with two fractions partitioned for
\(\log k\) and \(\log \Delta C\).
Assumptions for MLR
- All \(X_j\) measured with
no/minimal error
- Linearity between \(Y\) and \(BX\), in other words linear relationships
are assumed between \(Y\) and every
\(X_j\) adjusted for all other \(X\)-variables (hard to check!)
- Normally distributed residuals with constant variance
- use
qqnorm(residuals(mod)),
qqline(residuals(mod)), and plot(mod)
- plot \(|res|\) or \(res^2\) against \(\hat{Y}\) to detect variance heterogeneity
(no trend!)
- examine residuals for high leverage/influence
- Limited multicollinearity
- quick test: run
cor on predictor matrix, check for
large correlations
- formal test: Variance Inflation Factors (VIF) < 10 (ish)
Dealing with
multicollinearity
Why is this a problem?
- Numerical instability (hard to find parameter estimates)
- large CIs for regression slopes
- unsure importance of predictors (but could still be good overall
model).
Variance inflation factors
Ignoring \(y\) for a moment, we can
perform regressions of the \(x\)
variables against each other:
\[
x_i = b_0 + b_1x_1 \dots b_kx_k +\epsilon \mathrm{~;~excluding~x_i}
\]
Large \(R^2_i\) would argue for
redundancy of \(x_i\) (its information
is already contained in a linear combination of all other \(x\)-variables).
\(VIF_i\) is a transformation of
\(R^2_i\):
\[
\mathrm{VIF}_i = \frac{1}{1-R^2_i}
\] The VIF (name!) tells you by how much the SE of a regression
coefficient increases due to inclusion of additional \(x\)-variables:
\[
s_b = s_{b,\rho=0}\sqrt{\mathrm{VIF}}
\]
\(s_{b,\rho=0}\) is the standard
error of a regression coefficient, assuming that all predictors are
uncorrolated
VIF in R
# install.packages(car) # install the package, only need to do this once!
library(car)
## Loading required package: carData
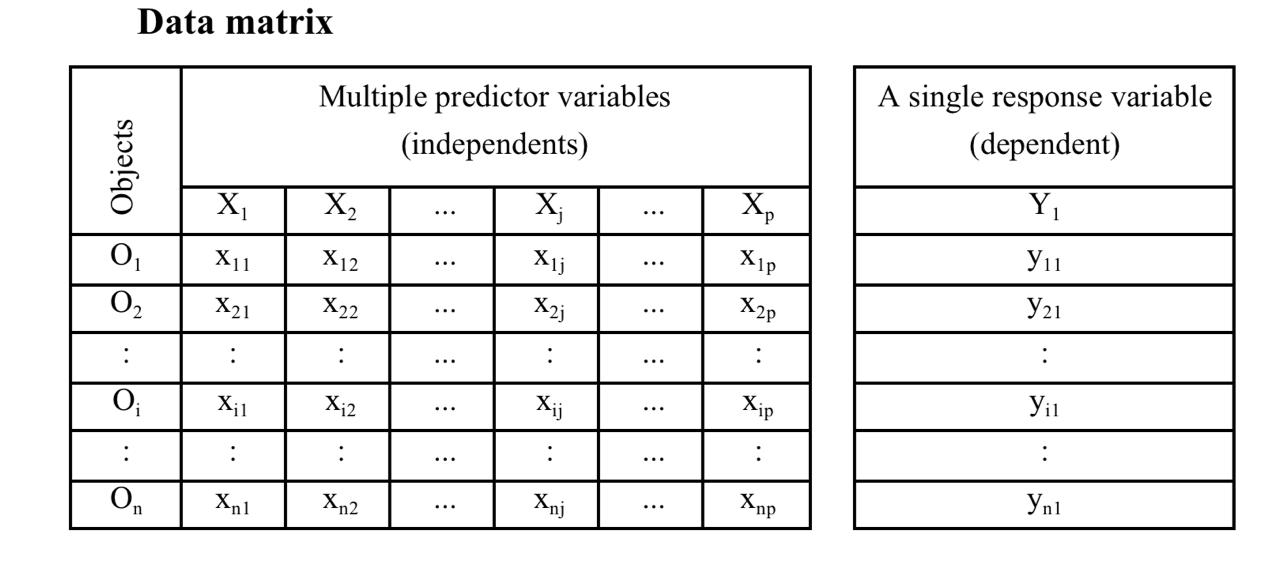
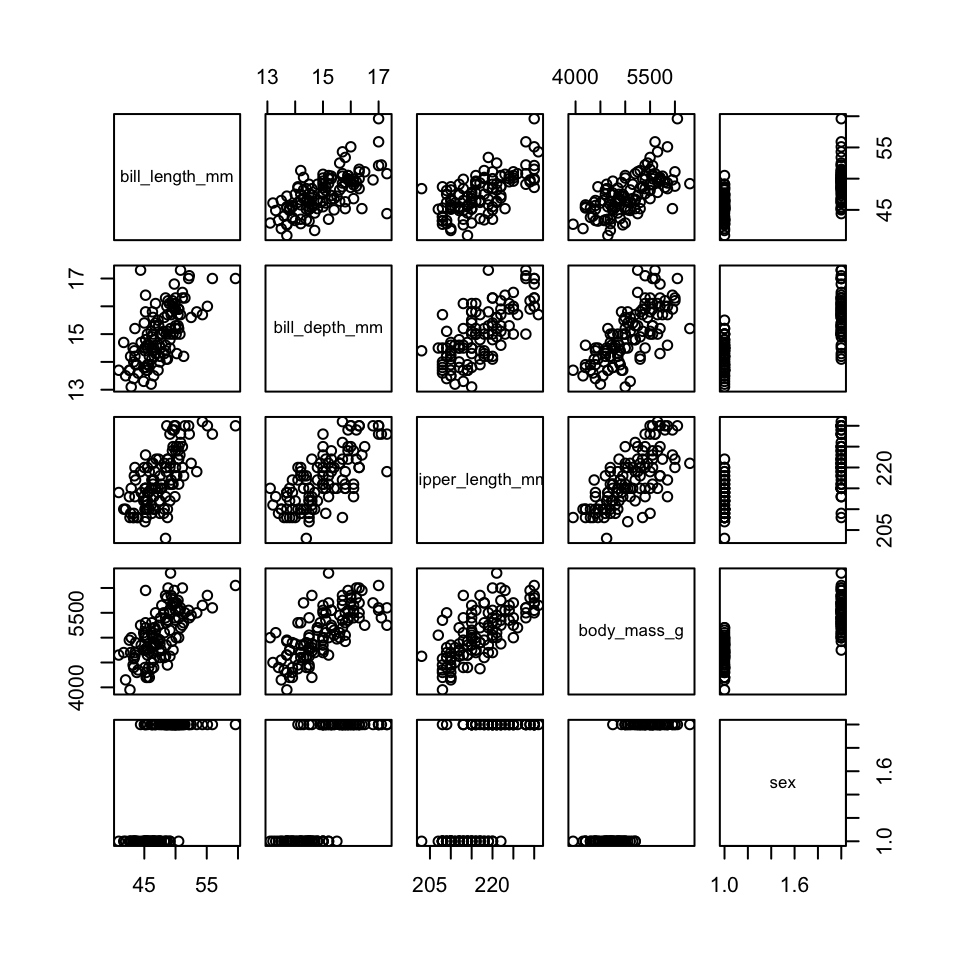
full_mod = lm(bill_length_mm ~ bill_depth_mm + flipper_length_mm +
body_mass_g + sex, data = penguins)
## Error in eval(mf, parent.frame()): object 'penguins' not found
vif(full_mod)
## Error: object 'full_mod' not found
Procedure: if any VIF > 10, drop the variable with the largest
VIF, repeat
Choosing predictors (models)
Simplest approach: fit a full model with all predictors, then drop
anything that is non-significant - at once or stepwise ;-)
Alternatively:
- start simple and add predictors
- do both, i.e. consider addition and removal of individual variables
at any point to result in an ‘optimized’ model
Caveats:
- Predictors may represent important hypotheses
- Predictors can influence other predictors!
- \(x_2\) is significant only if
\(x_1\) is in the model, but \(x_1\) is never significant
- Interactions must include all main effects:
- \(\mathbb{E}(y) = b_0 + b_1x_1 + b_2x_2 +
b_3x_1x_2\)
- A model with \(b_3\) must include
\(b_1\) and \(b_2\), even if non-significant!
- High-order terms (e.g., polynomials) must also include all
lower-order terms
- \(\mathbb{E}(y) = b_0 + b_1x_1 +
b_2x_1^2\)
- A model with \(b_2\) must include
\(b_1\)
Model building
- Stepwise model selection, implemented
step in R will
build a model for you automatically, adding or dropping terms in an
attempt to find a model that minimises AIC
- “Exhaustive” model building: Computation of all possible models =
all predictor combinations
- Any of these are ok approaches for exploration but
not for hypothesis testing
- p-values resulting from such a model are not useful
- We should view such models as hypotheses to be explored with further
data collection
- Unwise to speak of significance
Such models are prone to Overfitting:” irrelevant
predictors that correlate with the outcomes by chance result in a model
that fits the dataset well, but performs poorly when challenged with new
data (low transferability).
Validation
to ensure a model is fit for prediction
- Usage of additional or new data (or data formerly set aside) to
validate a model
- Leave-one-out cross-validation: Using a dataset with n cases, this
procedure repeats the model finding process n times leaving out 1 case
at a time. A predicted value is computed for each left-out case using
the respective model built without this case. A final plot of observed
vs. predicted values allows to assess the predictive capacity of the
model.
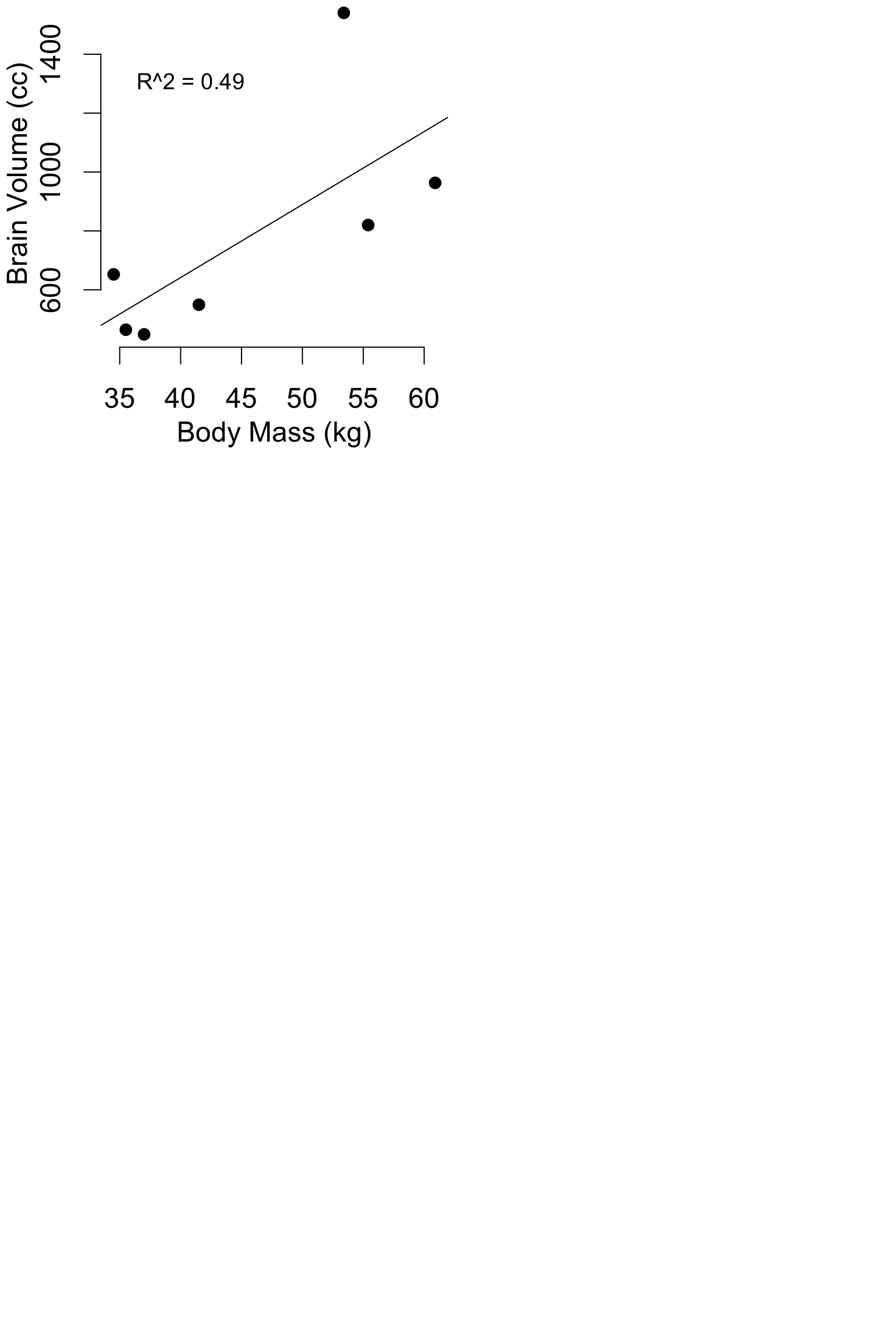
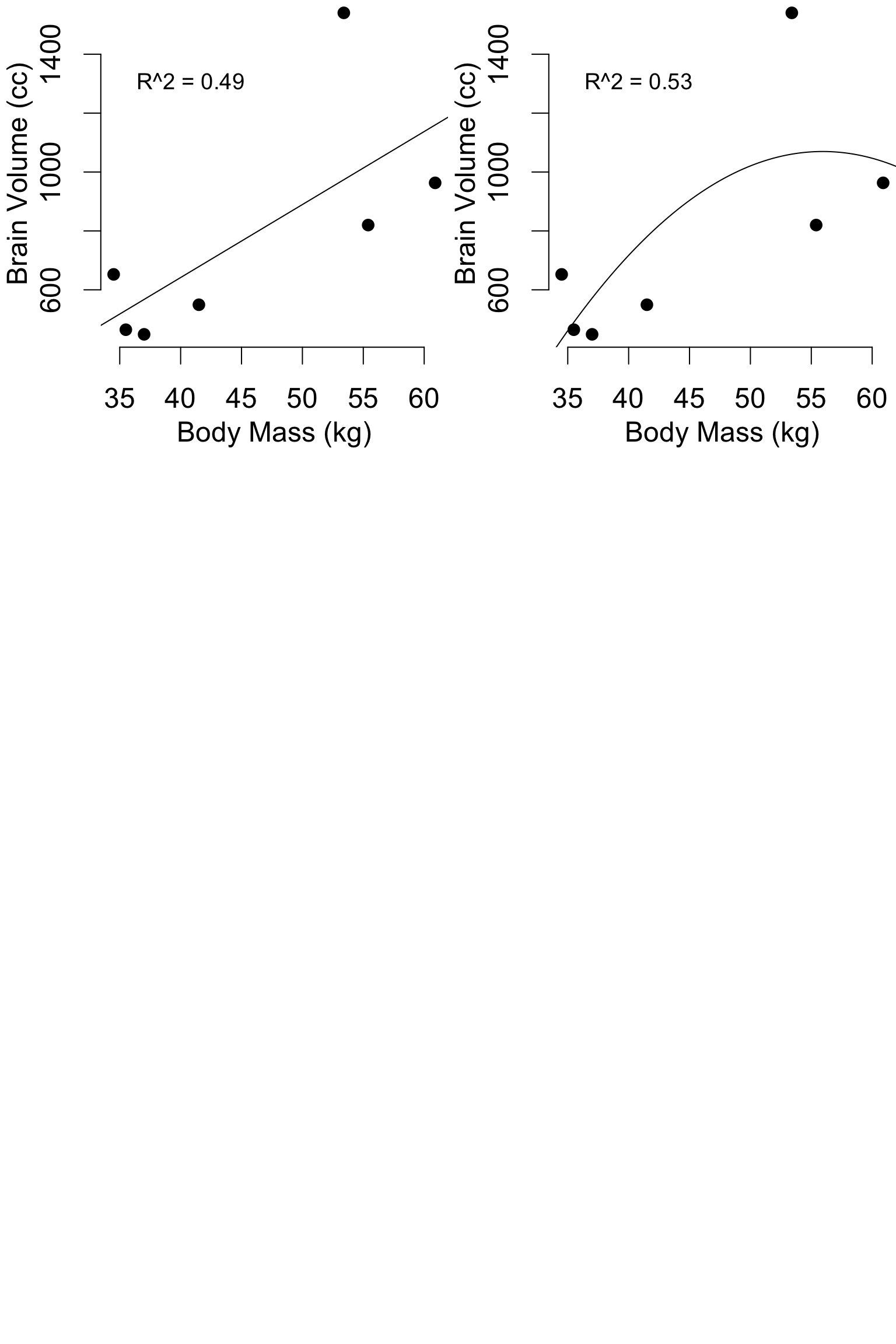
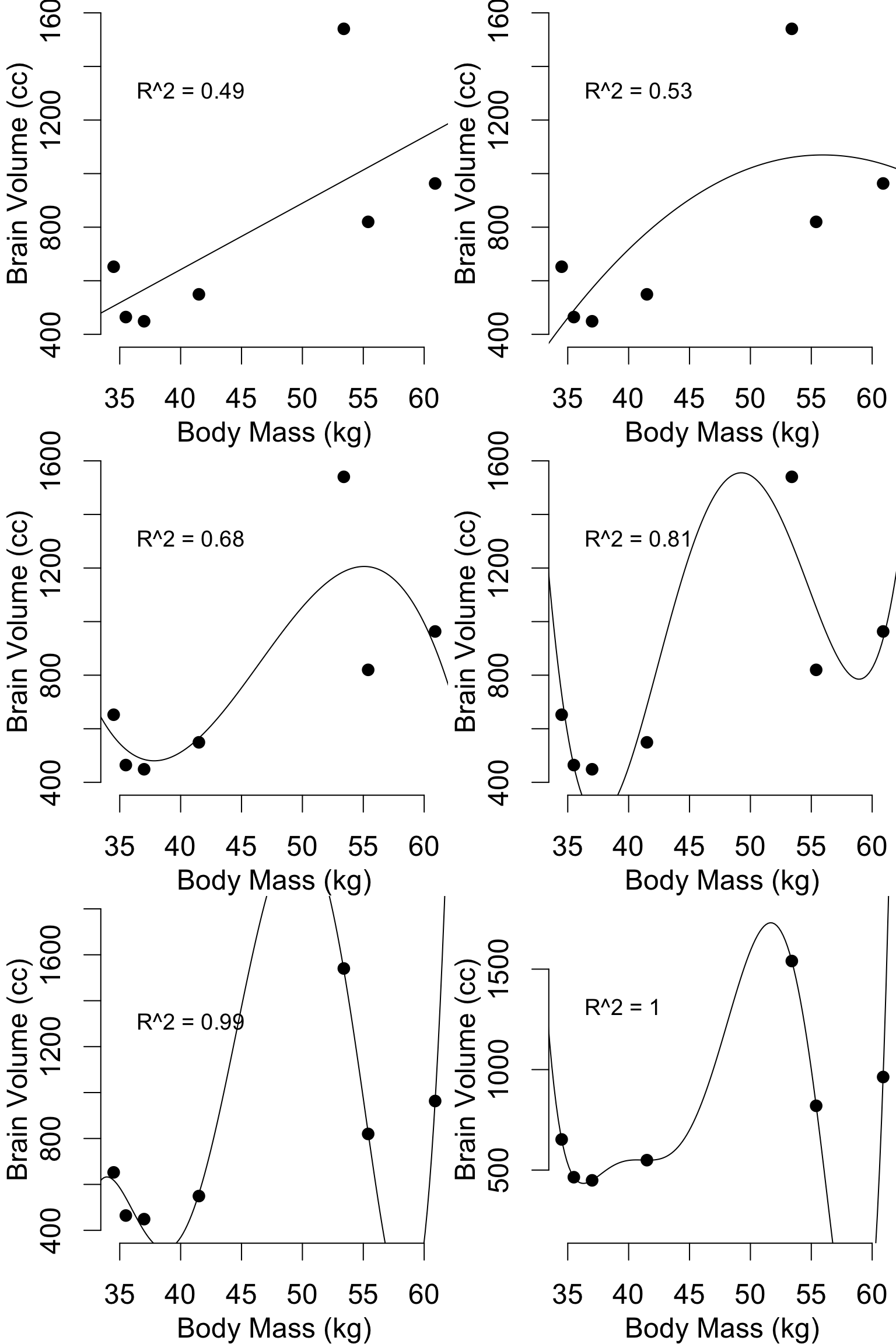
Pitfalls: Model flexibility
hom = data.frame(
body_mass_kg = c(34.5, 35.5, 37, 41.5, 55.4, 53.4, 60.9),
brain_volume_cc = c(652.4, 464.5, 448.8, 549.3, 819.9, 1540.4, 963.2)
)
mod1 = lm(brain_volume_cc ~ body_mass_kg, data = hom)
Pitfalls: Model flexibility
mod1 = lm(brain_volume_cc ~ body_mass_kg, data = hom)
mod2 = lm(brain_volume_cc ~ body_mass_kg + I(body_mass_kg^2), data = hom)
Pitfalls: Model flexibility
mod1 = lm(brain_volume_cc ~ body_mass_kg, data = hom)
mod2 = lm(brain_volume_cc ~ body_mass_kg + I(body_mass_kg^2), data = hom)
mod3 = lm(brain_volume_cc ~ body_mass_kg + I(body_mass_kg^2) + I(body_mass_kg^3), data = hom)
mod4 = lm(brain_volume_cc ~ body_mass_kg + I(body_mass_kg^2) + I(body_mass_kg^3) + I(body_mass_kg^4), data = hom)
mod5 = lm(brain_volume_cc ~ body_mass_kg + I(body_mass_kg^2) + I(body_mass_kg^3) + I(body_mass_kg^4) + I(body_mass_kg^5), data = hom)
mod6 = lm(brain_volume_cc ~ body_mass_kg + I(body_mass_kg^2) + I(body_mass_kg^3) + I(body_mass_kg^4) + I(body_mass_kg^5) + I(body_mass_kg^6), data = hom)
The curse of dimensionality
- High dimensional spaces (lots of \(x\) variables) require lots of data
- Rule-of-thumb minimum: \(n >
5k\)
- with large \(k\), even more is
needed (as the necessary n to cover multidimensional space increases as
a power law of k).
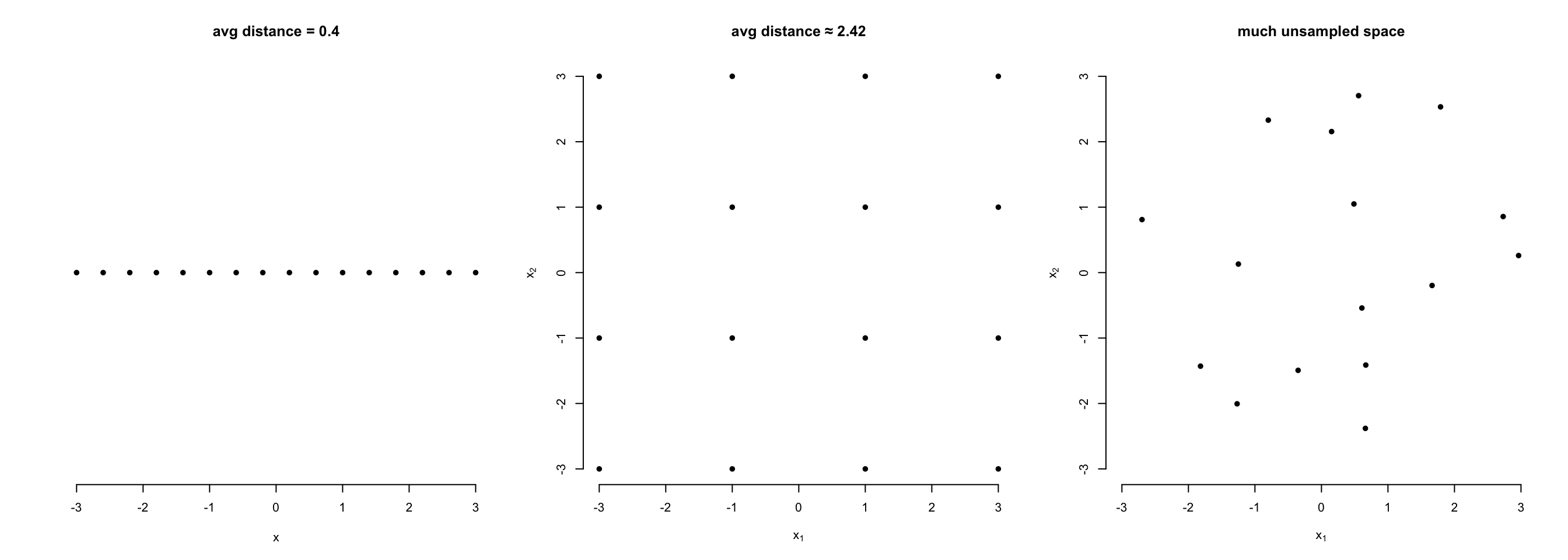
Assume predictors \(X_1\) and \(X_2\) and limited sampling effort of
n=16:
- When studying only one predictor, we can cover its entire range of
interest well.
- When studying two predictors with the same effort, our samples are
dispersed in the 2D-space. We can´t get the same density but still cover
the entire 2D-space in a regular grid.
- The more likely reality produces a dispersed distribution over the
2D-space with well and less well covered areas. The data becomes
sparse. Maintaining high sampling density becomes
increasingly difficult when more than two 2 dimensions are involved. We
don´t cover our predictors well enough anymore!
Presenting Results
Always:
- A complete description of the model, all variables, and whatever
variable selection method
- A table of regression parameters, std errors or confidence
intervals, p-values
- \(R^2\) or another metric of
goodness of fit
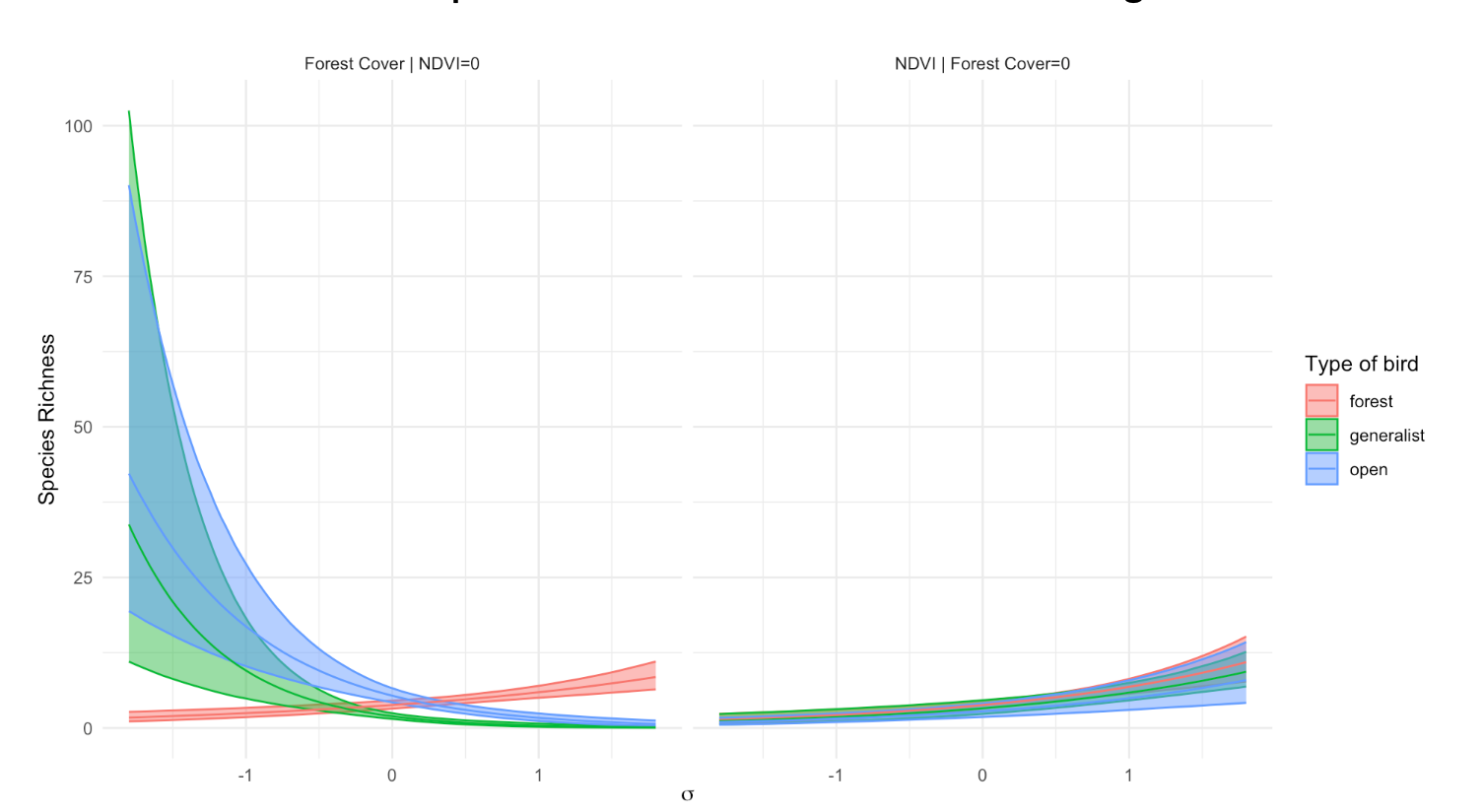
Graphical options
- Scatterplot-like representations not possible for >2
predictors
- Diagnostics (qq-plots, residulas vs fits) are even more
important!
- Partial response curves: effect of each variable,
holding others constant
When \[
Y = b_0+b_1 \cdot X_1+b_2*X_2
\] \[
Y_{adj} = Y-b_0-b_2*X_2
\] then \(Y_{adj}\) is adjusted
for the effect of \(X_2\) (and the
intercept \(b_0\)) and may be
meaningfully plotted against \(X_1\)
(when this variable is considered more important).
Last example
- Hypothesis tests give us false confidence about \(H_A\)!
Last example
One in 100,000 people have a condition, sigmocogititis, that causes
you to think too much about statistics.
- \(H_0\): I do not have the
disease
- \(H_A\): I have it!
We have a test with a type 1 error rate (\(\alpha\)) = 0.05, and a type 2 error rate
(\(\beta\)) of 0.
Last example
One in 100,000 people have a condition, sigmocogititis, that causes
you to think too much about statistics.
- \(H_0\): I do not have the
disease
- \(H_A\): I have it!
We have a test with a type 1 error rate (\(\alpha\)) = 0.05, and a type 2 error rate
(\(\beta\)) of 0.
I take the test, p < 0.05, and so I begin treating my
condition.
Last example
One in 100,000 people have a condition, sigmocogititis, that causes
you to think too much about statistics.
- \(H_0\): I do not have the
disease
- \(H_A\): I have it!
We have a test with a type 1 error rate (\(\alpha\)) = 0.05, and a type 2 error rate
(\(\beta\)) of 0.
I take the test, p < 0.05, and so I begin treating my
condition.
Problem: The probability that I have the disease is
only 0.0002!
If we test 100,000 people with unknown status, 5% (5000) will test
positive, but only one will have the condition. We made the wrong
decision in 4999/5000 of these cases!
Last example
One in 100,000 people have a condition, sigmocogititis, that causes
you to think too much about statistics.
- \(H_0\): I do not have the
disease
- \(H_A\): I have it!
We have a test with a type 1 error rate (\(\alpha\)) = 0.05, and a type 2 error rate
(\(\beta\)) of 0.
I take the test, p < 0.05, and so I begin treating my
condition.
Problem: The probability that I have the disease is
only 0.0002!
If we test 100,000 people with unknown status, 5% (5000) will test
positive, but only one will have the condition. We made the wrong
decision in 4999/5000 of these cases!
- In statistics, often called the base rate
fallacy
- In science, we call this the replication
crisis
- Considering only \(\alpha\) and
\(H_0\) means we neglect to consider
the plausibility of \(H_A\)